Nonlinear dynamics with neural networks
Preliminary Examination
Nonlinear Artificial Intelligence Laboratory, North Carolina State University
May 8, 2024
Table of Contents
Motivation
Motivation: Why Neural Networks?
- The preeminent computational tool of the contemporary world.
- Differentiable, optimizable, and scalable.
- Emergent uses in and out of Physics1.

![]()

Motivation: Why Nonlinear Dynamics?
- Captures complexity.
- Formal, well-established framework.
- Emergent uses in and out of Physics.
Avalanche activity cascades in a sandpile automaton | Vortex street formed by flow past a cylinder | Turing patterns in a reaction-diffusion model
Animation by William Gilpin
Motivation: Why Nonlinear Dynamics for Neural Networks?
- Optimization is inescapably nonlinear2.
- Neural networks are inherently nonlinear.
- Scope of nonlinearities in neural networks is underexplored.

|
Trainability fractal by Jascha Sohl-Dickstein
Motivation: Why Neural Networks for Nonlinear Dynamics?
- Nonlinear dynamical systems are computationally expensive to solve.
- Paradigm of solution as an element of a distribution translates naturally to neural networks.
- Data-driven methods accommodate realistic complexity.
Background Neural Networks and optimization
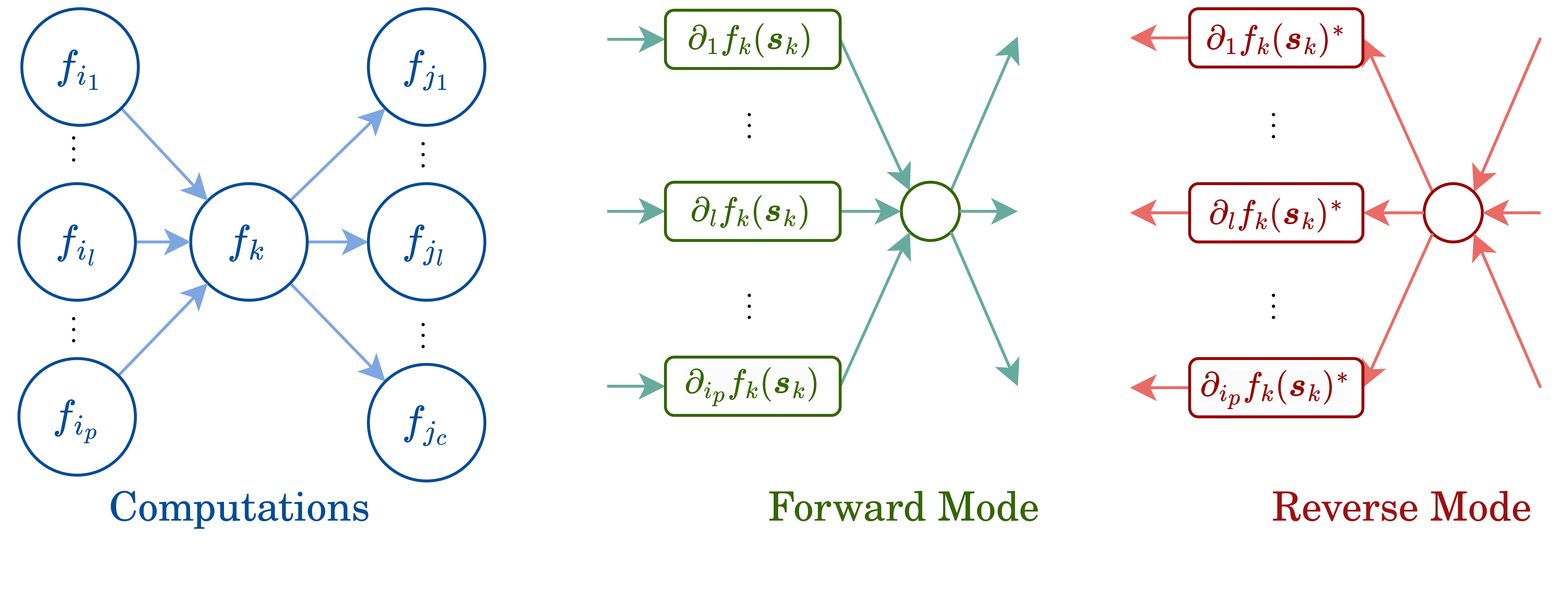
Background: Differentiable Computing
- Paradigm where programs can be differentiated end-to-end automatically, enabling optimization of parameters of the program3.
- Techniques to differentiate through complex programs is more than just deep learning.
- Can be interpreted probabilistically or as a dynamical system.
![autodifferentiation diagram]()
Background: Neural Networks
φ:Rd→RNLTl:RNl−1→RNlσ:R→R x∈RdWl∈RNl×Nl−1bl∈RNl
Background: Backpropagation
Consider a differentiable loss function L,
δL=∇φL⊙σ′(TL)δl=((wl+1)⊺δl+1))⊙σ′(Tl)∂L∂blj=δlj∂L∂wljk=Tl−1kδlj
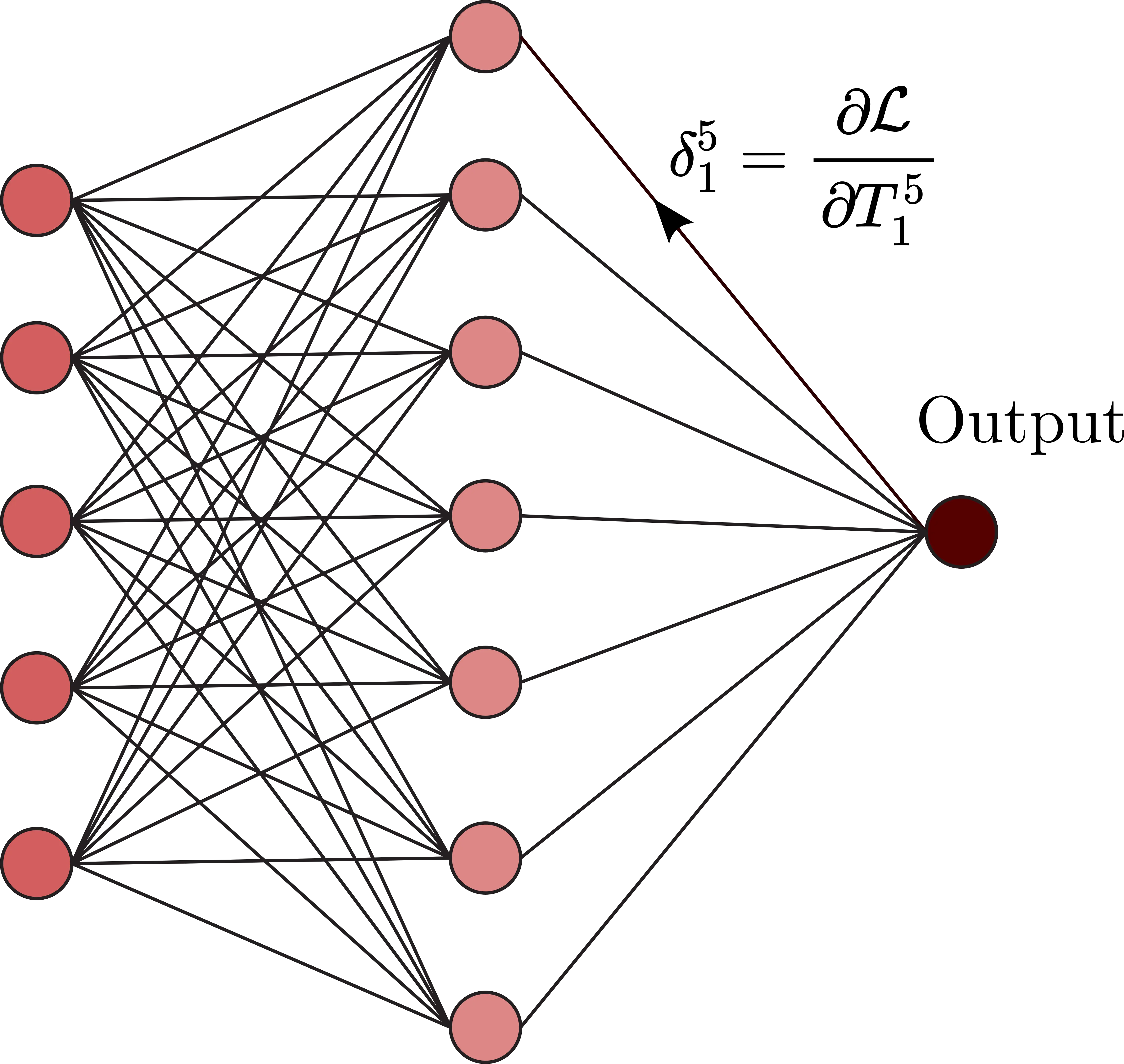
The tunable parameters can then be updated by: θ←θ−η∇θL
Background: Loss Functions
- Neural networks compute a probability distribution on the data space.
- Constructing a suitable differentiable loss function gives the path to optimization of a neural network. Common loss functions include:
- Mean Squared Error L(θ)=∑Ni=1(yi−f(xi;θ))2
- Cross Entropy L(θ)=−∑Ni=1yilog(f(xi;θ))
- Kullback-Leibler Divergence L(θ)=∑Ni=1yilog(yif(xi;θ))
Loss functions are combined and regularized to balance the tradeoff between model complexity and data fit.
Background: Optimization
- To find the best model parametrization, we minimize the loss function with respect to the model parameters.
- That is we compute, L⋆:=infθ∈ΘL(θ) assuming an infimum exists.
- To converge to a minima the optimizer needs an oracle O, i.e. evaluation of the Loss function, its gradients, or higher order derivatives. Then, for an algorithm A, θt+1:=A(θ0,…,θt,O(θ0),…,O(θt),λ), where λ∈Λ is a hyperparameter.
Stochastic Gradient Descent, Adam, and RMSProp are common optimization algorithms for training neural networks.
Background: Meta-Learning
- Improve the learning algorithm itself given the experience of multiple learning episodes.
- Base learning: an inner learning algorithm solves a task defined by a dataset and objective.
- Meta-learning: an outer algorithm updates the inner learning algorithm.
Algorithms for meta-learning are still in a nascent stage with significant computational overhead.
Figure by John Lindner
Background: Physics-Informed Neural Networks(PiNNs)
- Synthesizing data with differential equation constraints.
- Physics as a weak constraint in a composite loss function or a hard constraint with architectural choices.
- Symplectic constraints to the loss function gives Hamiltonian Neural Networks4.

Background: Coordinates matter
Neural networks are coordinate dependent. The choice of coordinates can significantly affect the performance of the network.
Adapted from Heliocentrism and Geocentrism by Malin Christersson
Metalearning Activation functions
(Published, US and International Patent Pending)Foundation
- Most complex systems showcase diversity in populations.
- Artificial neural network architectures are traditionally layerwise-homogenous
- Will neurons diversify if given the opportunity?
Insight
- Activation functions can themselves be modeled as neural networks.
- Activation function subnetworks are optimizable via metalearning.
- Multiple subnetwork initializations allow the activations to diversify and evolve into different communities.
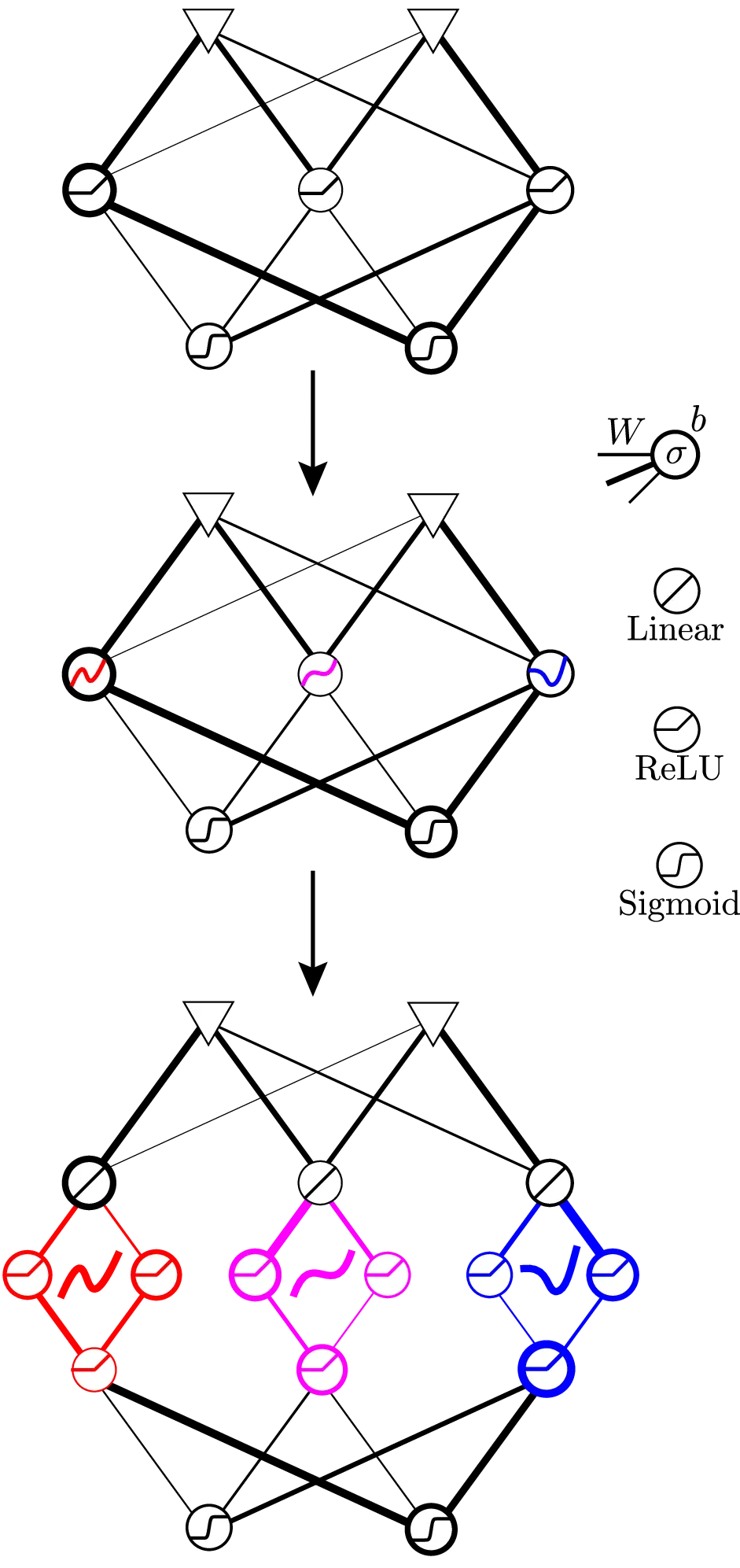
Figure from Publication
Methodology
- Developed a metalearning framework to optimize activation functions.
- Tested the algorithm on classification and regression tasks for conventional and physics-informed neural networks.
- Showed a regime where learned diverse activations are superior.
- Gave preliminary analysis to support diversity in activation functions improving performance.
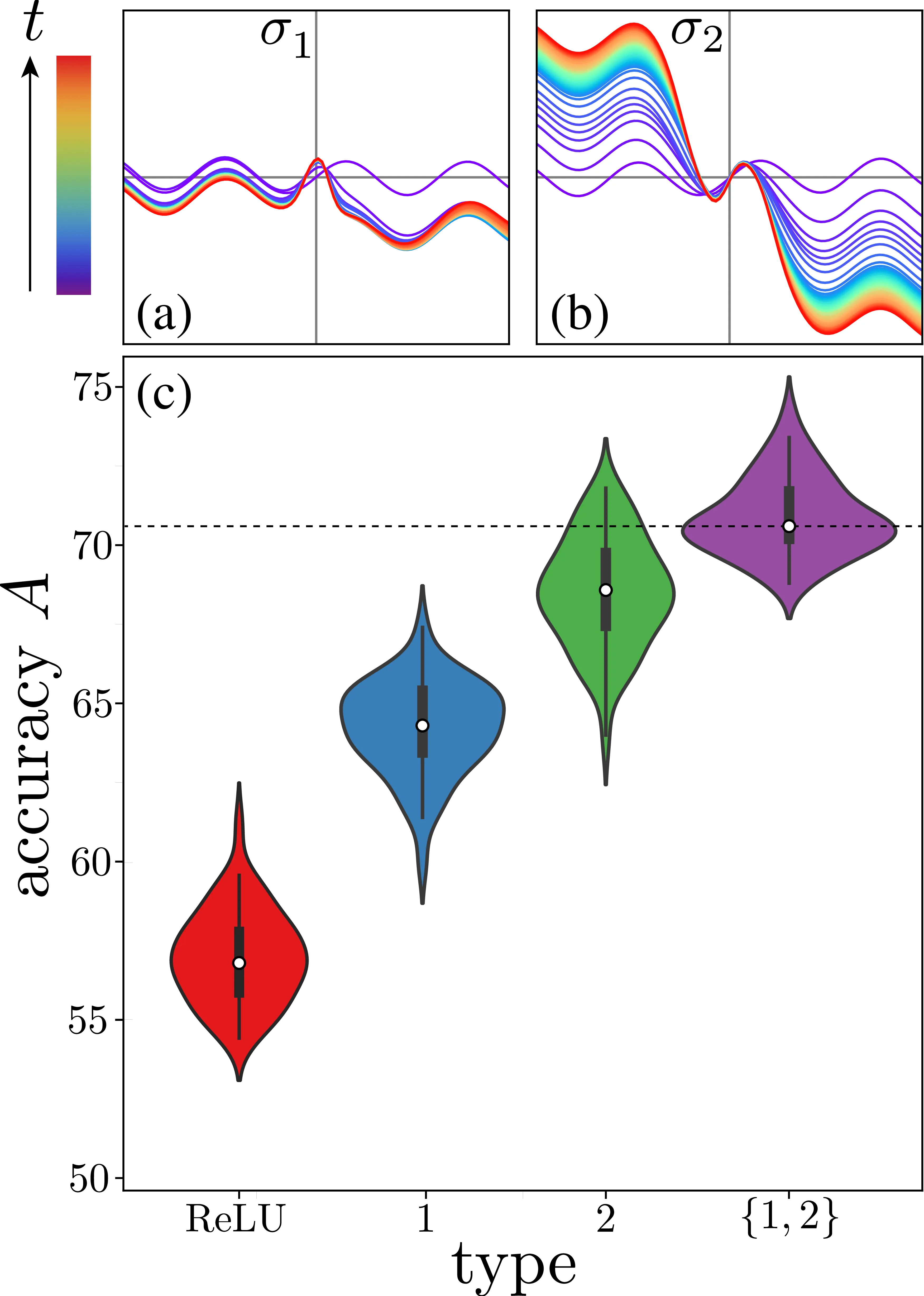
Figure from Publication
Results: Scaling

Figure from Publication
Results: Real World Data
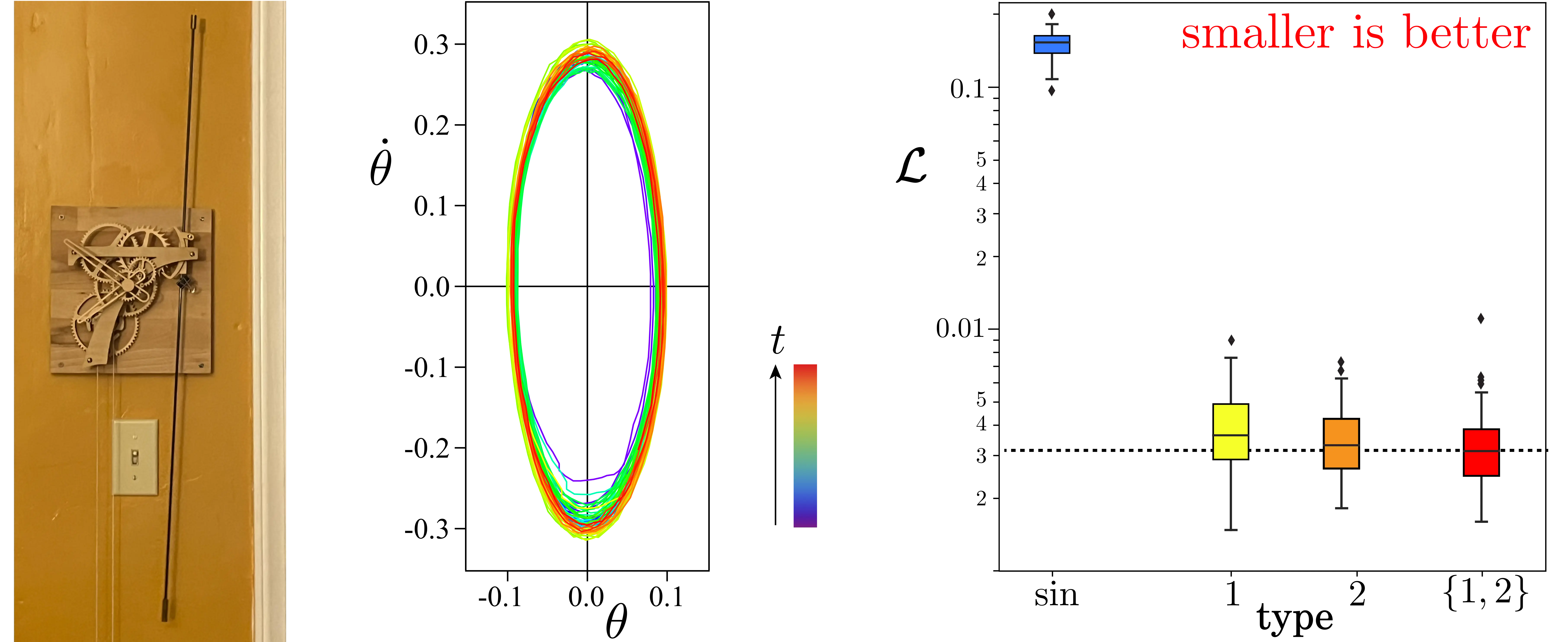
Figure from Publication
Analysis: Participation Ratio
Estimate change in dimensionality of network activations
Nr=R=(trC)2trC2=(∑Nn=1λn)2∑Nn=1λ2n
where λn are the co-variance matrix C’s eigenvalues for neuronal activity data matrix. The normalized participation ratio r=R/N5.
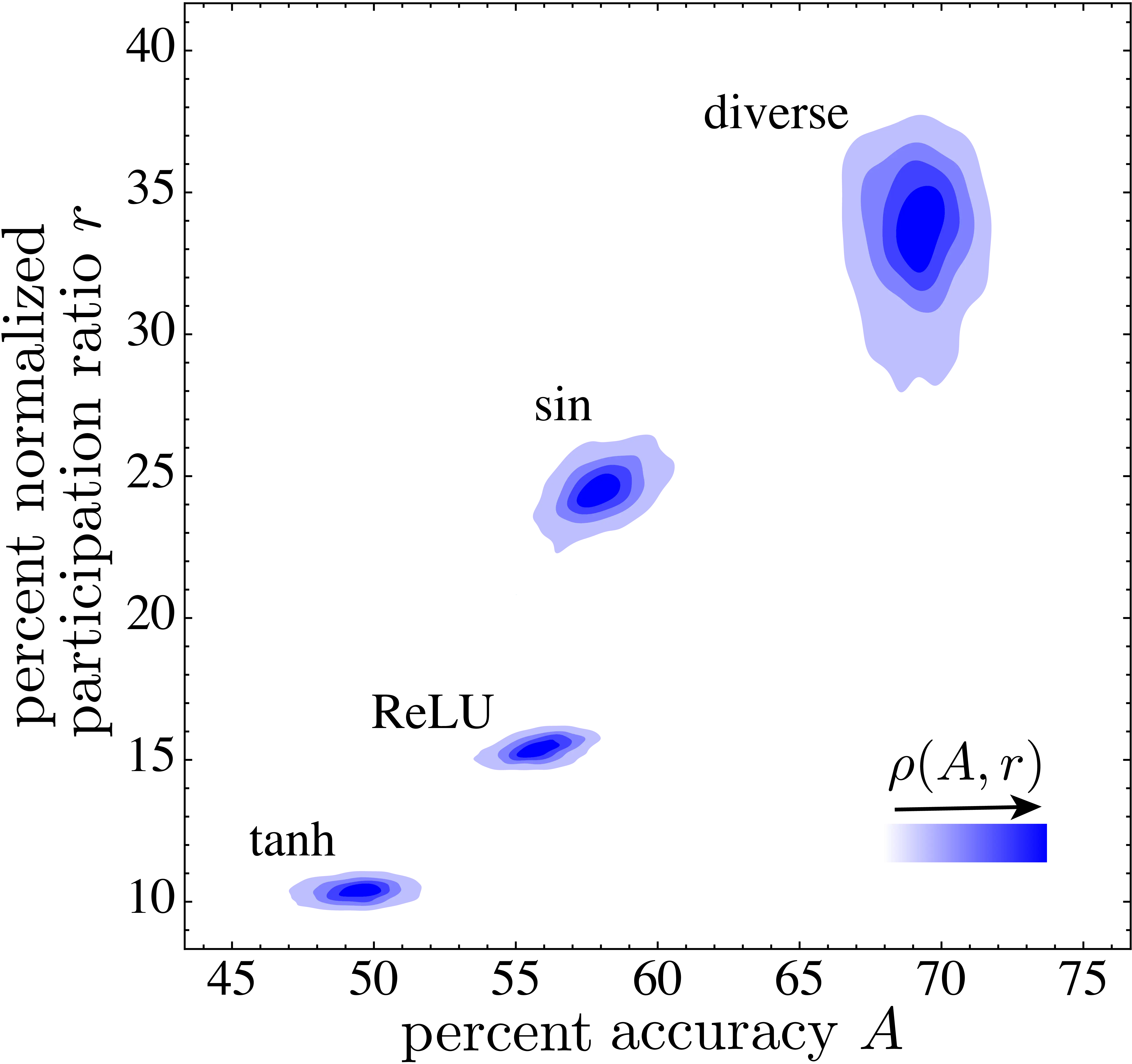
Diverse activation functions use more of the network’s capacity.
Figure from Publication
Conclusions
- Learned Diversity Networks discover sets of activation functions that can outperform traditional activations.
- These networks excel in the regime of low data few shot learning.
- Due to the nature of metalearning, the memory overhead is significant concern for scaling.
Speculations: Achieving stable minima
Optimization of a neural network with shuffled data is a noisy descent.
This can be modeled with the Langevin equation:
dθt=−∇L(θt)dt+√2D⋅dWt with noise intensity D=(η)L(θ)H(θ⋆)6
Speculations: Structure and universality to diverse activations
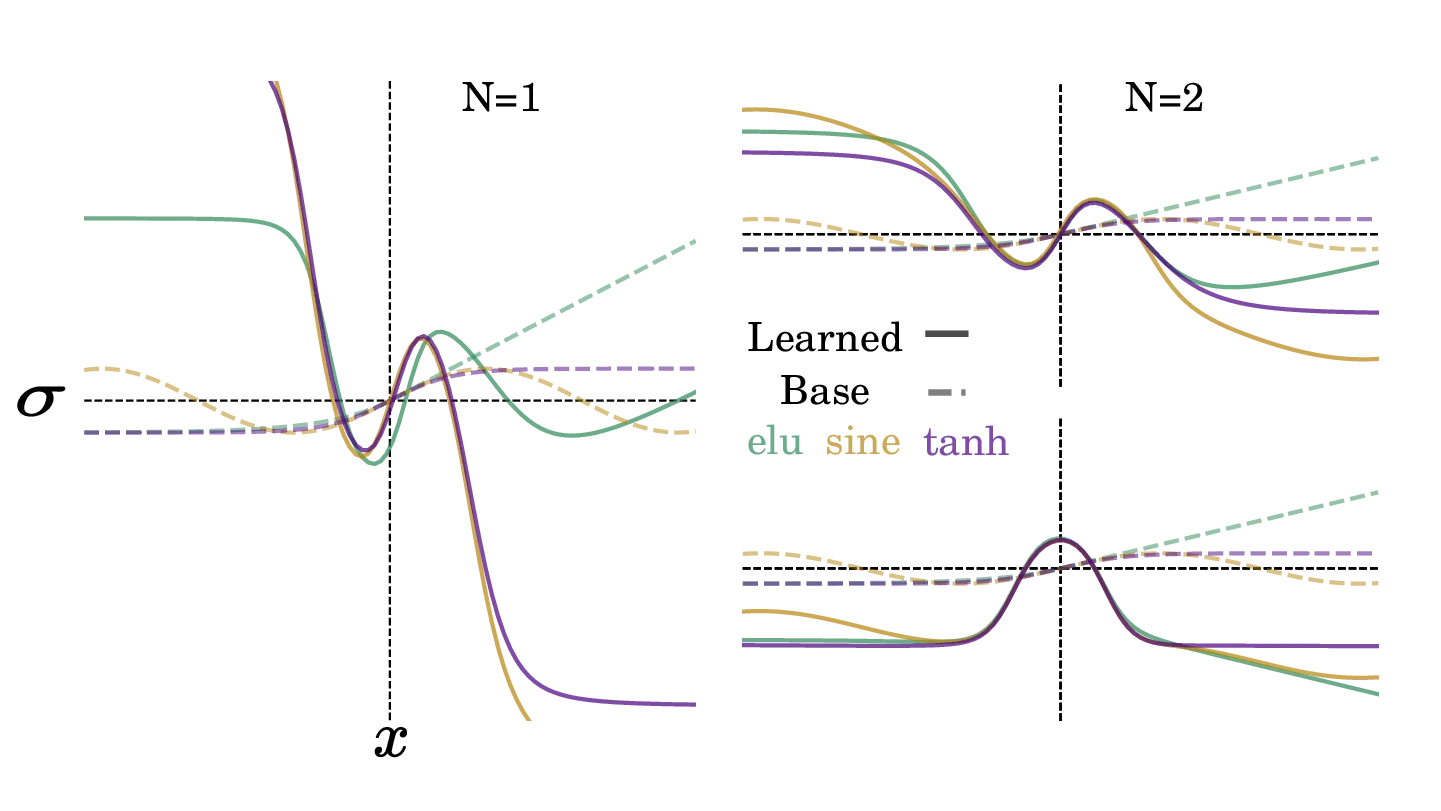
- Learned activation functions appear qualitatively independent of the base activation function.
- The odd and even nature of the learned functions suggest that the network is learning to span the space of possible activation functions.
Background: Control and Chaos
Background: Hamilton Jacobi Bellman(HJB) Equation
For a control system with state x(t) and control u(t), dxdt=f(x(t),u(t))dt
H(x,u,t0,tf)=Q(x(tf),tf)+∫tft0L(x(τ),u(τ))dτV(x(t0),t0,tf)=minu(t)H(x(t0),u(t),t0,tf)−∂V∂t=minu(t)[L(x(t),u(t))+∂V∂xTf(x(t),u(t))]
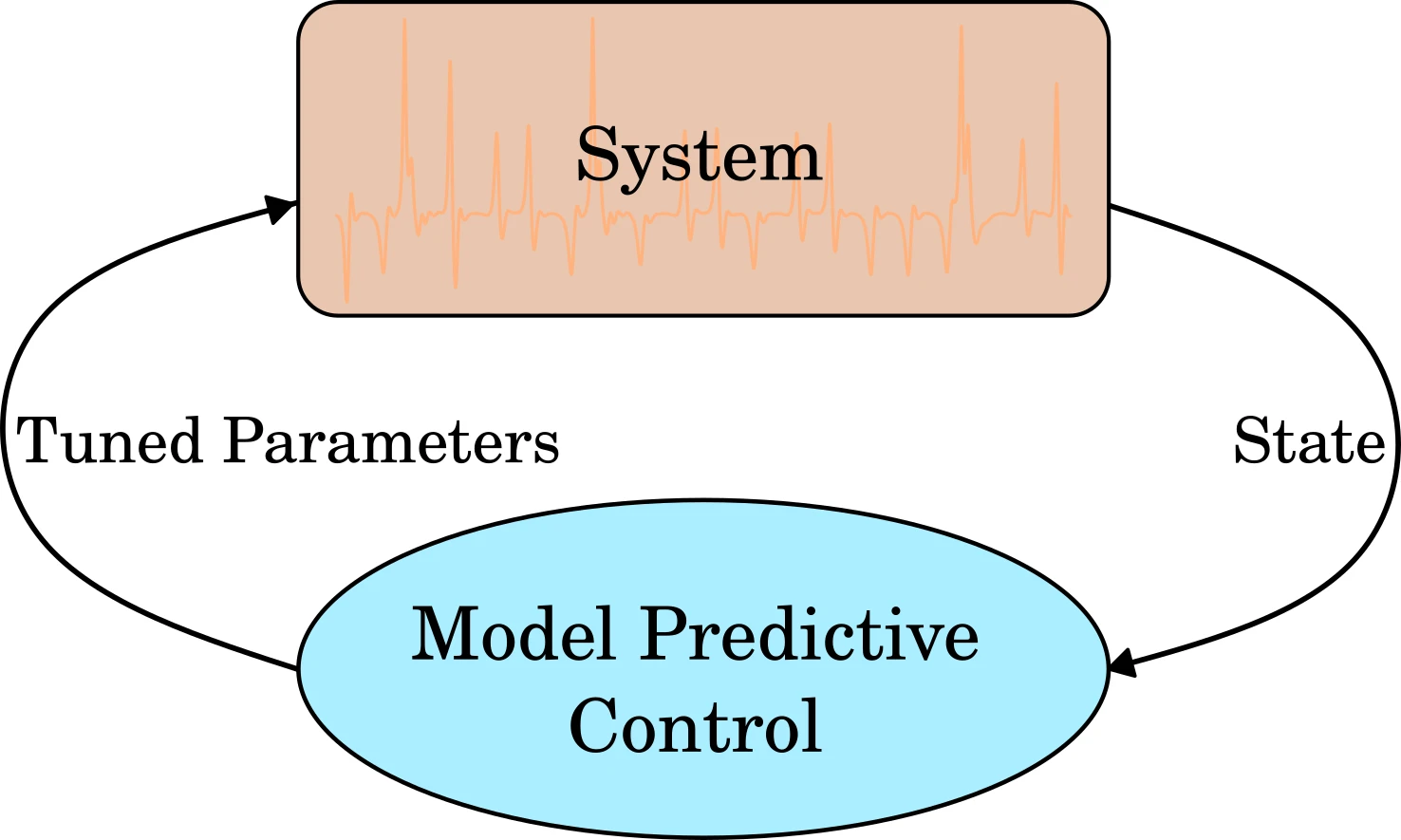
Background: Model Predictive Control
Control scheme where a model is used for predicting the future behavior of the system over finite time window7.
|
Animations from do-mpc documentation
Background: Chaos
Let X be a metric space. A continuous map f:X→X is said to be chaotic on X if:
|
Background: Traditional Chaos Control
Relies on the ergodicity of chaotic systems9,10.


Background: Chaotic Pendulum Array11
l2n¨θn=−γ˙θn−lnsinθn+τ0+τ1sinωt+κ(θn−1+θn+1−2θn)
Background: Kuramoto Oscillator12
| ˙θi=ωi+λN∑j=1sin(θj−θi) |
Synchronizing fireflies video from Robin Meier
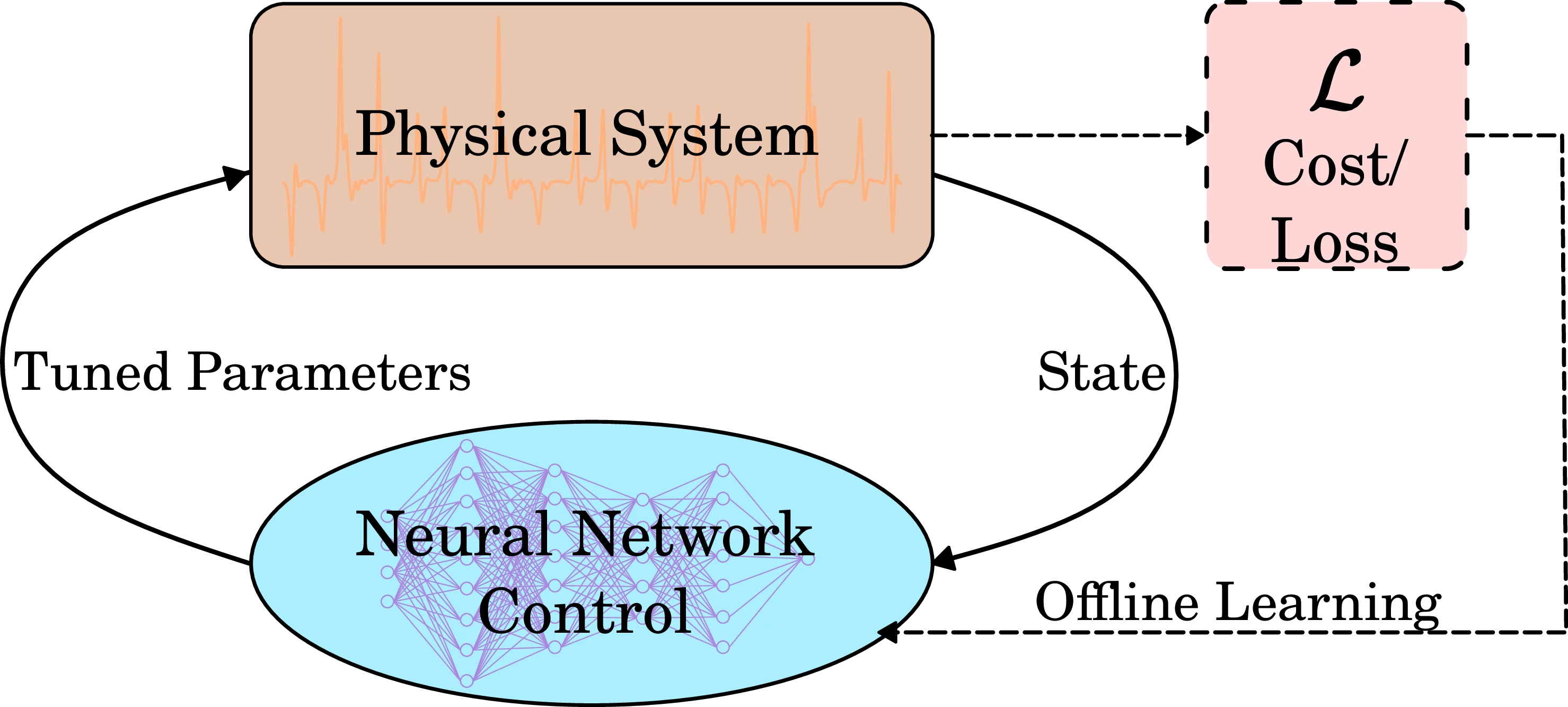
Neural Network control of chaos
Insight
- Optimal control of network dynamics involves minimizing a cost functional.
- Traditional control approaches like Pontryagin’s (maximum) principle or Hamilton-Jacobi-Bellman equations are analytically and computationally intractable for complex systems.
- Neural networks based on neural ODES can approximate the optimal control policy13.
Methodology
Results: Kuramoto Grid
Results: Pendulum Array
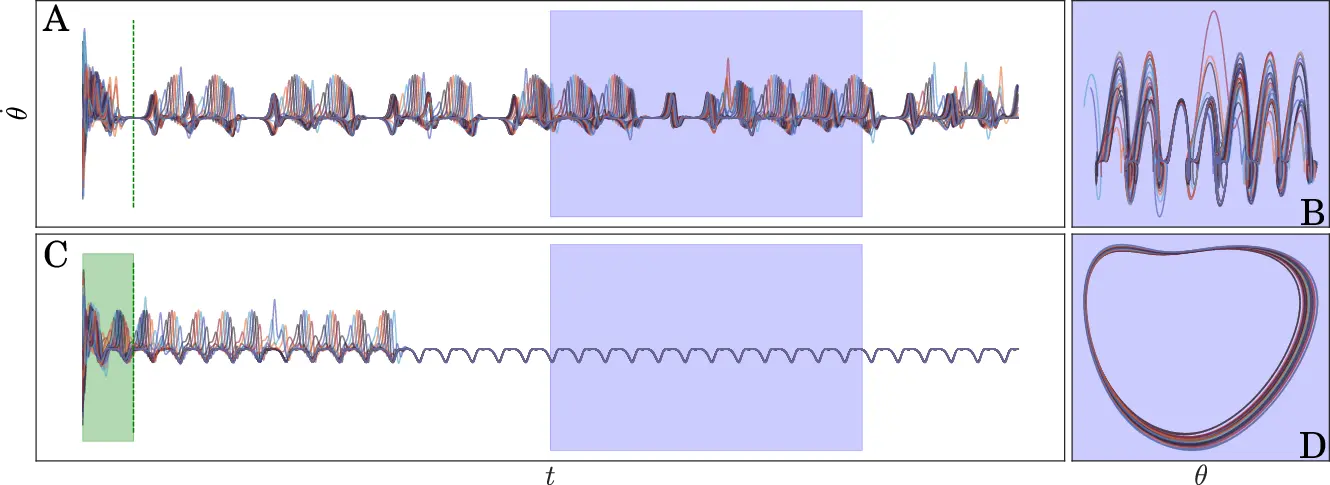
Future Work: Exotic Dynamics14
˙θi=ωi+λN∑j=1Aijsin(θj−θi−α)
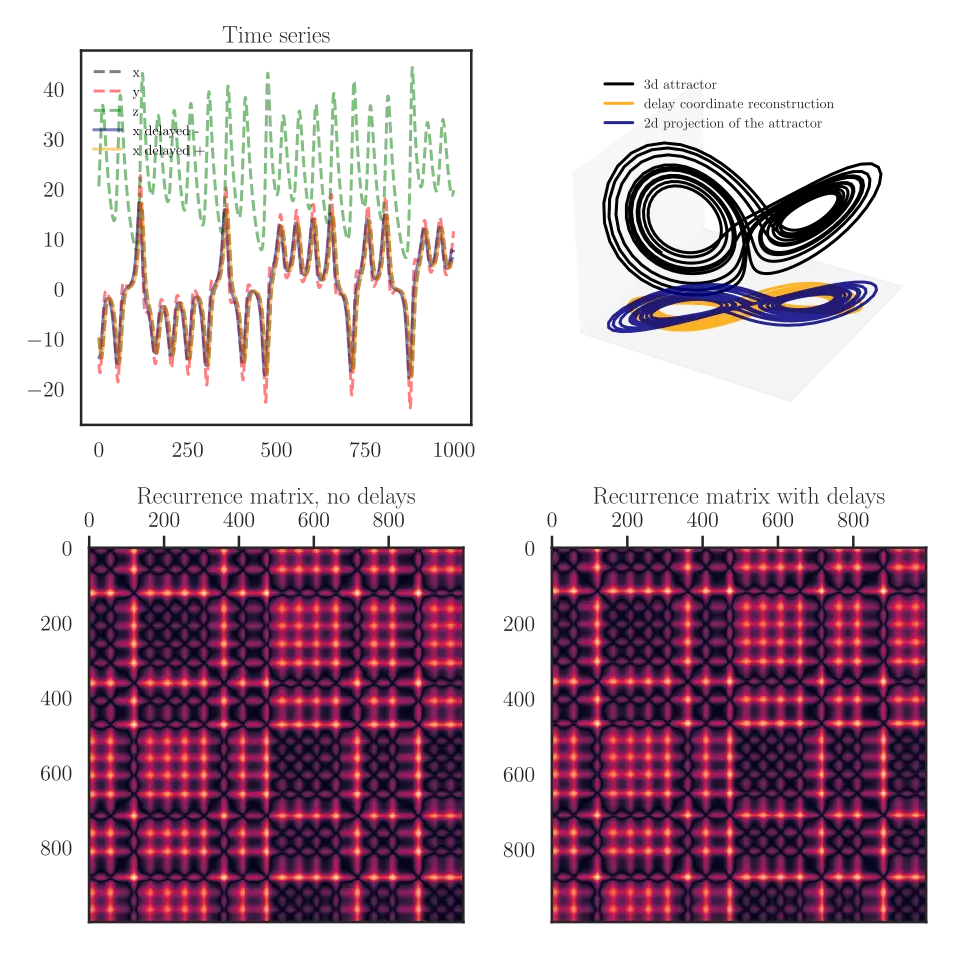
Future Work: Recurrence matrices in L15
Background: Dynamics and symmetries
Background: Group theory for Dynamical Systems
Let Γ act on Rn and f:Rn→Rm . Then f is said to be Γ-equivariant if f(γx)=γf(x) for all x∈Rn and γ∈Γ16.
For dynamical systems, for a fixed point f(x⋆)=0, γx⋆ is also a fixed point.
Isotropy subgroup: Let v∈Rn:Σv={γ∈Γ:γv=v}
Fixed pt subspace: Let σ∈Σ⊆Γ. Fix(Σ)={v∈Rn:σv=v}
Thm: Let f:Rn→Rm be a Γ-equivariant map and Σ⊆Γ. Then f(Fix(Σ))⊆Fix(Σ).
Background: Group Equivariant Neural Networks
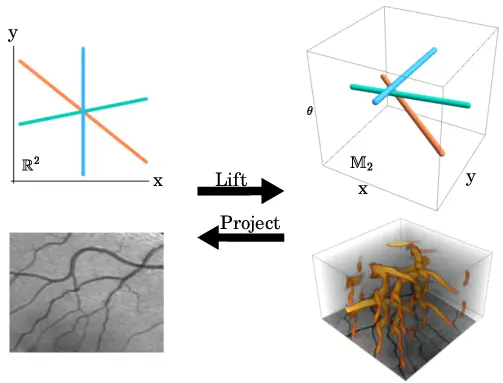
Group equivariant NN work through lifting convolutions to the group space, and then projecting back to the original space17.
Figure adapted from Bart Smets et al.
Symmetries of controllers
Insight
- Dynamical systems often obey symmetries.
- Controllers are essentially dynamical systems.
- Is there a computationally viable mapping between the symmetries of the system and the controller?
Methodology
- Analyze the controllers from the previous sections for symmetries using group equivariant autoencoders
- Construct controllers that respect the symmetries of the system
- Compare the performance of symmetric to conventional controllers.
Expectation
- Viability test for group equivariant neural networks in control systems.
- Mapping between the symmetries of the system and the controller.
- Performance analysis of symmetric controllers.
Conclusion
- Non-traditional treatments of neural networks let us better capture nonlinearity.
- Standard paradigms of Geometry, Statistics, and Algebra for understanding nonlinear systems are augmented by neural networks.
- The interplay of Physics, Mathematics, and Computer Science gives us the best shot at understanding complex systems
Deliverables
● Publication and Patent on Metalearning Activation functions.
◕ Publishable article on Neural Network Control of Chaos.
◔ Thorough study of the symmetries of controllers.
◑ Codebase for the above studies.
◔ Dissertation detailing the discoveries and pitfalls found throughout.
Estimated time of completion: August 2025
Acknowledgements

Background image from Jacqueline Doan
References
Backup slides
Hyperparameters, integrators, and tolerances
Metalearning Activation functions:
MNIST1D: 1 hidden layer of 100 neurons, activation of 50 hidden neurons. 100 initializations averaged. RMSprop, Real Pendulum: same other than 50 initializations. Pytorch and Jax frameworks used.
Neural Network control of chaos:
Control and dynamics integration via diffrax Jax library for neural ODEs. TSit5 algorithm for ODE integration with PID controller with rtol 1e-7 and atol 1e-9. Stratanovich Milstein solver for SDE integration with PID controller with rtol 1e-7 and atol 1e-9. 1000 epochs Controller training with only 1/5 data for the first half. Implemented in Jax.
Universal approximation theorem
M(σ)=span{σ(wx−θ):w∈Rn,θ∈R}
Theorem 1: Let σ∈C(R). Then M(σ) is dense in C(Rn), in the topology of uniform convergence on compacta, if and only if σ is not a polynomial18.
For Neural Networks,
Theorem 2: Let σ be any continuous sigmoidal function. Then finite sums of the form G(x)=∑Ni=1αiσ(wTix+bi) are dense in C(In). i.e. ∀f∈C(In) and ϵ>0, there is a sum G(x) such that maxx∈In|f(x)−G(x)|<ϵ19.
Informally, at least one neural network exists that can approximate any continuous function on In=[0,1]n with arbitrary precision.
SGD via gradient flows
Gradient descent: xn+1=xn−γ∇f(xn) where γ>0 is the step-size. Gradient flow is the limit where γ→0.
There are two ways to treat SGD in this regime,
Consider fixed times t=nγ and s=mγ.
- Convergence to gradient flow
Given the recursion xn+1=xn−γ∇f(xn)−γϵn,
applying this m times, we get:
X(t+s)−X(t)=xn+m−xn=−γm−1∑k=0∇f(X(t+skm))−γm−1∑k=0εk+n in the limit, X(t+s)−X(t)=−∫t+st∇f(X(u))du+0 which is just the gradient flow equation.
- Convergence to Langevin diffusion
Given the recursion xn+1=xn−γ∇f(xn)−√2γϵn,
applying this m times, we get:
X(t+s)−X(t)=xn+m−xn=−γm−1∑k=0∇f(X(t+skm))−√2γm−1∑k=0εk+n The second term has finite variance ∝2s. When m tends to infinity,
X(t+s)−X(t)=−∫t+st∇f(X(u))du+√2[B(t+s)−B(t)]
This limiting distribution is the Gibbs distribution with density exp(−f(x))
Argument from Francis Bach
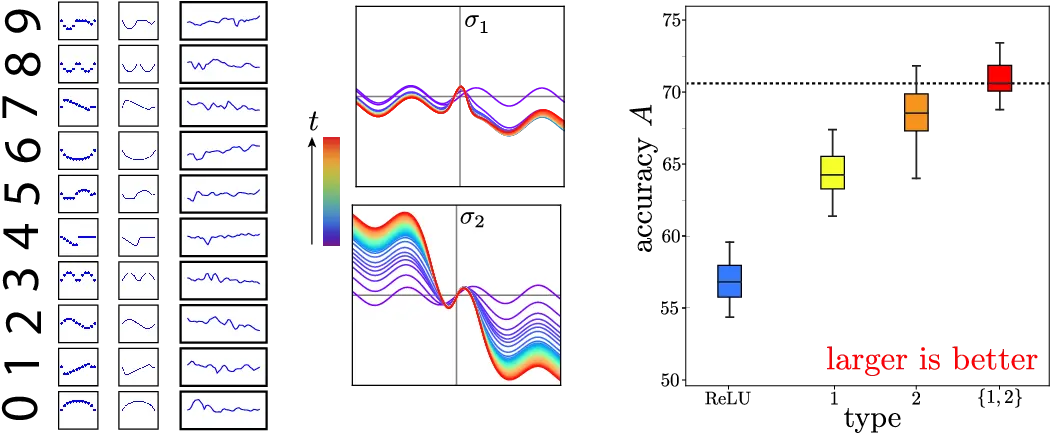
1DMNIST
Neural ODEs
Forward propagation: x(t1)=ODESolve(f(x(t),t,θ),x(t0),t0,t1)Compute loss: L(x(t1))a(t1)=∂L∂x(t1)
Back propagation: [x(t0)∂L∂x(t0)∂L∂θ]=ODESolve([f(x(t),t,θ)−a(t)T∂f(x(t),t,θ)∂x−a(t)T∂f(x(t),t,θ)∂θ],[x(t1)∂L∂x(t1)0|θ|],t1,t0)
HJB Derivation Sketch
Bellman optimality equation: V(x(t0),t0,tf)=V(x(t0),t0,t)+V(x(t),t,tf) dV(x(t),t,tf)dt=∂V∂t+∂V∂xTdxdt=minu(t)ddt[∫tf0L(x(τ),u(τ))dτ+Q(x(tf),tf)]=minu(t)[ddt∫tf0L(x(τ),u(τ))dτ]
⟹−∂V∂t=minu(t)[L(x(t),u(t))+∂V∂xTf(x(t),u(t))]
Pontryagin’s Principle
Let (x⋆,u⋆) be an optimal trajectory-control pair. Then there exists a λ⋆ such that, λ⋆=−∂H∂x and H(x⋆,u⋆,λ⋆,t)=minuH(x⋆,u,λ⋆,t) and by definition, x⋆=∂H∂λ
Stochasticity and noise
We can add intrinsic noise to it by adding a noise term ξ with a strength σ: dxdt=f(x,t)+σ(x,t)ξ
Then the rectangular reimann construction is equivalent to: f(t)≈∑ni=1f(^xi)χΔxi
where f(^xi) are constants. This approximation is exact in the limit of n→∞.
For the stochastic case, the rectangular construction is equivalent to: ϕ(t)≈∑ni=1ˆeiχΔxi Then the integral is: ∫T0ϕ(t)dWt=n∑i=1ˆeiΔWi
Here, the coefficients ˆei are not constants but random variables since we are allowed to integrate σ which depends on Xt.
Recurrence plots caveat emptor
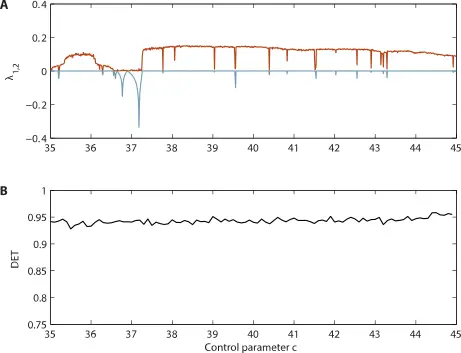
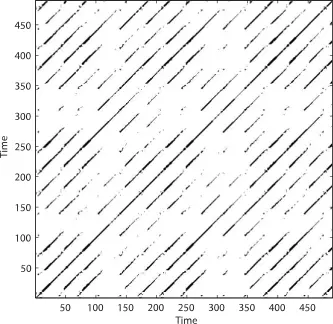
Lyapunov exponent and Recurrence plot from Recurrence Plot Pitfalls
Neural network architectures
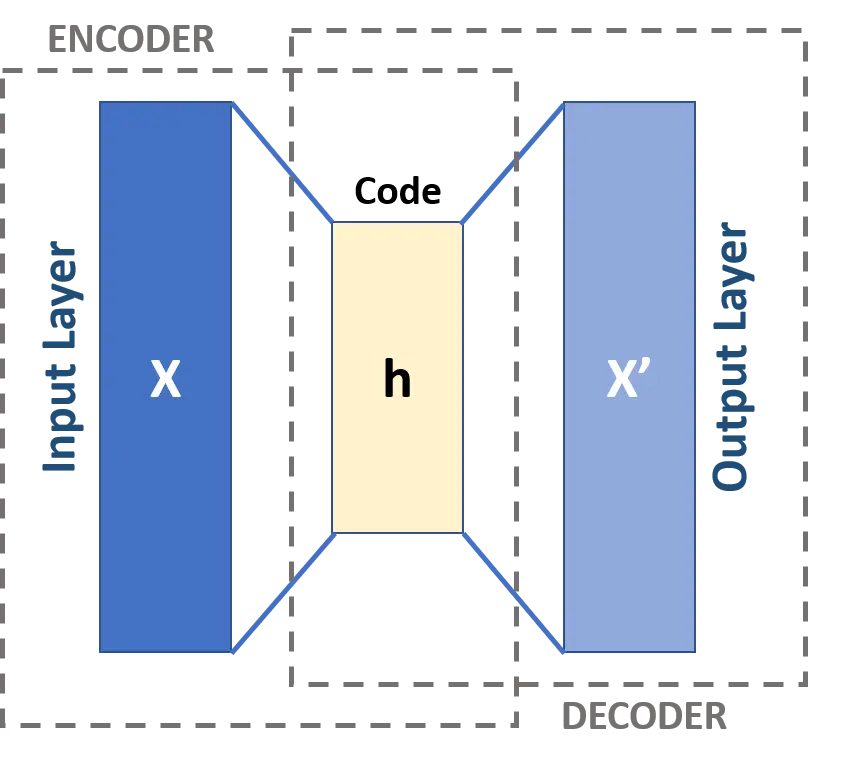
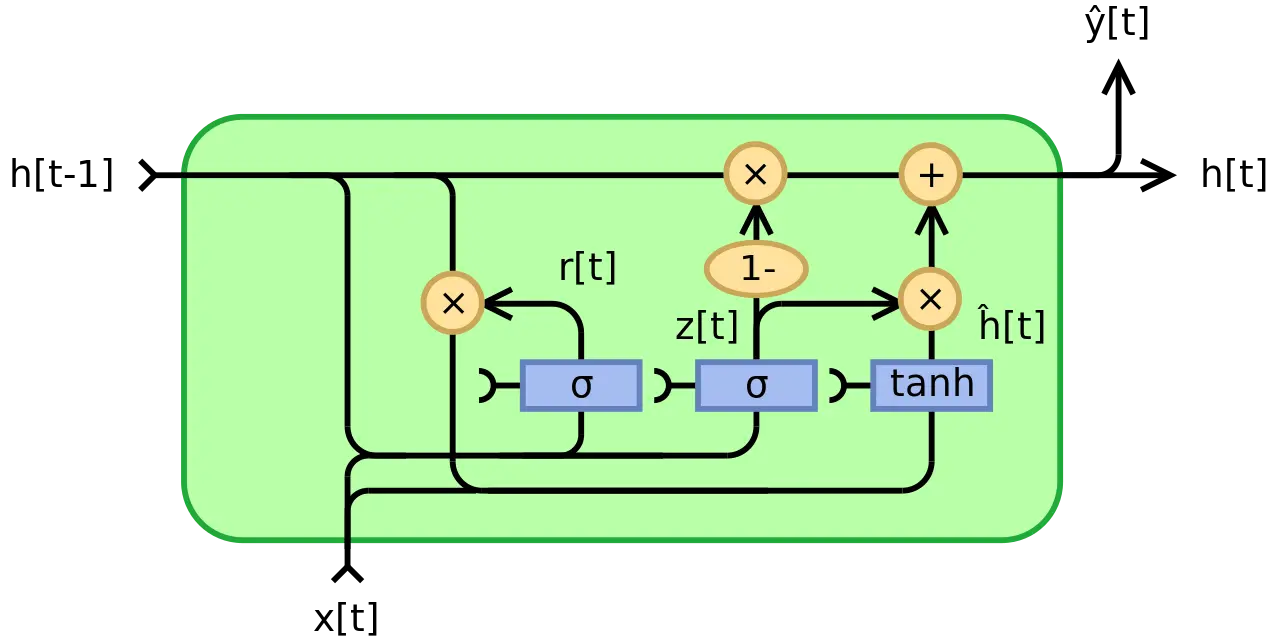
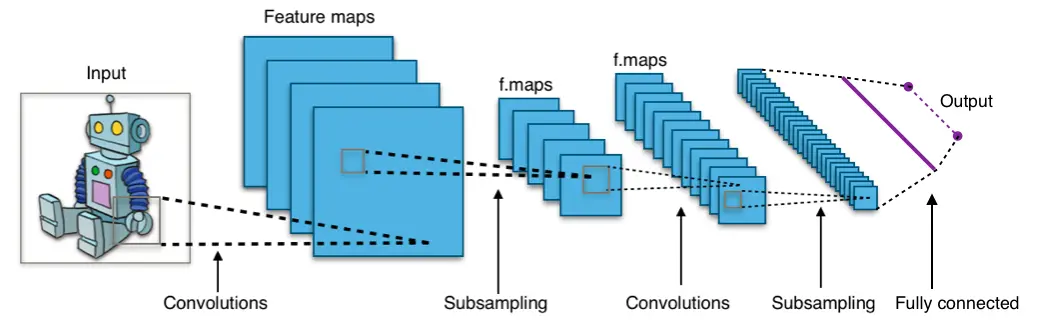
All images from associated wikipedia pages (Autoencoder, GRU, CNN)

